
Code Meet AI Weekly: GPT‑5, EU AI Rules, Open‑Weight Models, and World Models
Code Meet AI Weekly: OpenAI’s GPT‑5 lands, the EU’s AI obligations kick in, open‑weight models heat up, xAI leans into openness, DeepMind pushes “world models. First week of august 2025

Intro
Welcome to the News & Insights edition of Code Meet AI. This is your weekly signal in the noise—built for software engineers and tech entrepreneurs who want actionable takeaways, not hype. Use this to decide which tools to pilot, where to place bets, and how to keep your skills and products ahead.
This week: OpenAI’s GPT‑5 lands, the EU’s AI obligations kick in, open‑weight models heat up, xAI leans into openness, DeepMind pushes “world models,” and Apple reshapes the answer layer. I’ve added concrete actions and business opportunities for builders.
1) OpenAI launches GPT‑5
Link: https://openai.com/index/introducing-gpt-5/
GPT‑5 is a unified system: a fast model, a deeper “thinking” model, and a router that picks the right one per task. OpenAI claims fewer hallucinations, better instruction following, and stronger coding/health/multimodal performance. GPT‑5 Pro adds longer “thinking” for harder tasks. Early rollout router issues made it feel “dumber” for some users; OpenAI acknowledged and patched.
Insights
Practical coding uplift: OpenAI reports 74.9% on SWE‑bench Verified and 88% on Aider Polyglot. That puts it ahead of most “reasoning” peers on repo‑level bug‑fix tasks. If you’re evaluating agents-in-IDE or repo copilots, expect fewer dead-ends and better tool orchestration (parallel/sequenced calls).
Router = new UX surface: The model picker is becoming a policy. For teams, this is a signal to formalize routing rules: when to “think,” when to speed-run answers, and how to expose that toggle to users.
Safety shift from refusals to “safe completions”: Expect fewer hard refusals and more useful, bounded answers—this aligns with dual‑use domains (security, bio) where partial guidance can be safe and still helpful.
Long‑context matters again: If you’re building agents that ingest long logs/specs/reviews, GPT‑5’s long-context retrieval and lower hallucination rates will reduce scaffolding hacks and prompt gymnastics.
“Curriculum by prior models” trend: OpenAI and others increasingly bootstrap training with synthetic data generated by earlier models (think automated tutoring, critiques, and task generation). Done well, it speeds capability growth and reduces reliance on scarce human labels; done poorly, it amplifies model biases and can cause “model-on-model” error compounding. Expect more “self‑play curriculum” papers and tighter evaluations on synthetic-data quality in the coming months.
If you run Cursor/Copilot/Windsurf/JetBrains pilots: A/B GPT‑5 vs your current best on your repo tasks; measure tool-call error rate, patch acceptance, and time-to-green.
Decide your “reasoning policy”: default quick mode with a “think hard” switch, or route by task class.
2) EU General‑Purpose AI (GPAI) obligations kick in
1- Commission press: https://ec.europa.eu/commission/presscorner/detail/en/ip_25_1787
2- Legal analysis: https://www.dlapiper.com/en-hk/insights/publications/2025/08/latest-wave-of-obligations-under-the-eu-ai-act-take-effect
From Aug 2, 2025, GPAI providers face duties: technical documentation, copyright policy, and training‑data summaries. The EU AI Office and national authorities are live, with penalties phasing in.
Insights
EU’s regulatory gravity: Even if you’re US‑ or Asia‑first, enterprise procurement will adopt EU‑style requirements.
Still, maybe as EU want a safer AI, but the race world is worldwide: As China and USA are pushing new models each time and innovate/ compete in that. EU Regulate.
3) OpenAI releases free, customizable open‑weight models (Apache 2.0)
Coverage: https://www.theguardian.com/technology/2025/aug/05/openai-meta-launching-free-customisable-ai-models
Model card: https://openai.com/index/gpt-oss-model-card/
Open‑weight models under Apache 2.0—commercially friendly, fine‑tunable, and deployable in VPC/on‑prem. Not fully open source (weights yes; not full training stack), but a big move against Llama/DeepSeek.
Insights
Great for privacy‑sensitive or latency‑sensitive workloads; easy LoRA/PEFT tuning on standard GPUs.
Apache 2.0 = real commercial freedom: use, modify, distribute, and a patent grant—no copyleft, just notices. This competes directly with Meta’s Llama licensing and lowers total cost for startups/enterprises needing on‑prem or sovereign deployments.
Stack strategy: These models are sized for fine‑tuning/LoRA on commodity GPUs—great for domain‑specific copilots with strict privacy or latency needs.
4) xAI to open source Grok 2 next week
Link: https://www.reuters.com/business/musk-says-xai-will-open-source-grok-2-chatbot-2025-08-06/
Insights
More reproducibility and fairer benchmarks.
Inspectability matters for public‑sector/regulated buyers who need weight access.
Competitive pressure: With OpenAI’s open‑weight move and xAI opening Grok 2, the bar for “transparent enough” rises—especially for government and regulated buyers.
5) DeepMind unveils Genie 3 “world model”
A world model for realistic, physics‑aware simulation—useful for training robots/AVs and sim‑driven agents.
Insights
Engineers: Sim‑first < simulation first> training can cut real‑world trial costs. Expect better sim‑to‑real transfer tooling.
Gaming implications:
Generative game loops: Worlds, levels, and quests that adapt in real time to player style—new “infinite game” genres.
Smart NPCs: Agents trained in sims that persist skills and memory across sessions; more emergent behaviors.
Toolchains: Designers become “prompt directors,” steering world constraints rather than hand‑authoring assets.
Indie leverage: Prototype full experiences with small teams; production becomes curating AI‑generated content.
New infra: Runtime generation shifts costs from storage to compute; you’ll need budget‑aware content generation and safety filters to block unwanted outputs.
For enterprise: If you simulate logistics, support, or training, expect better fidelity simulators and cheaper data generation for RL/agent training.
6) Apple forms team to build an AI “answer engine”
Link: https://techcrunch.com/2025/08/03/apple-might-be-building-its-own-ai-answer-engine/
Insights
Siri/Safari/Spotlight could expose richer answer surfaces via intents and on‑device models; register clear actions your app can perform. Is is the start of unified device with AI capability?
Less dependence on partners: Apple moving beyond external LLMs (and the Google deal) signals deeper on‑device/in‑ecosystem retrieval/QA.
Surfaces that matter: Siri, Safari, Spotlight, and app intents could expose a unified “Answers” layer—great for devs who wire into Apple’s intents and on‑device models.
Distribution risk: If you rely on “default assistant” traffic, plan for Apple-native answer experiences that bypass web/app funnels.
7) Anthropic proposes “persona vectors”
Link: https://techxplore.com/news/2025-08-anthropic-theyve-ai-evil.html
A method to identify and steer latent “persona vectors” (e.g., sycophancy, hallucination, “evil”), potentially at training time (“vaccination”) or inference time.
Insights
New alignment knob: Identifying latent “persona vectors” and steering them lets you dial down sycophancy/hallucination without tanking overall capability—potentially a more surgical alternative to coarse RLHF.
Training‑time “vaccination”: Inducing undesirable personas during training can increase robustness against those behaviors later (less persona drift) with smaller capability loss than post‑hoc patching.
Product impact: Imagine shipping assistants with measurable “sycophancy ≤ X%” or “hallucination ≤ Y%” targets that are enforced by vector steering—then monitored in production.
Limits: Requires well‑defined traits; generalization across models/traits still needs validation.
8) Anthropic “Opus 4.1” launch
Publicly, the Claude 4 family includes Opus 4.1.
https://www.anthropic.com/news/claude-opus-4-1
Claude 4 Sonnet plays in the same “reasoning + agent” lane as GPT‑5/Gemini 2.5. Earlier releases showed strong repo‑level coding and memory behavior (e.g., Terminal‑bench, SWE‑bench gains).
Opus 4.1 advances our state-of-the-art coding performance to 74.5% on SWE-bench Verified. It also improves Claude’s in-depth research and data analysis skills, especially around detail tracking and agentic search
Definitions (quick reference)
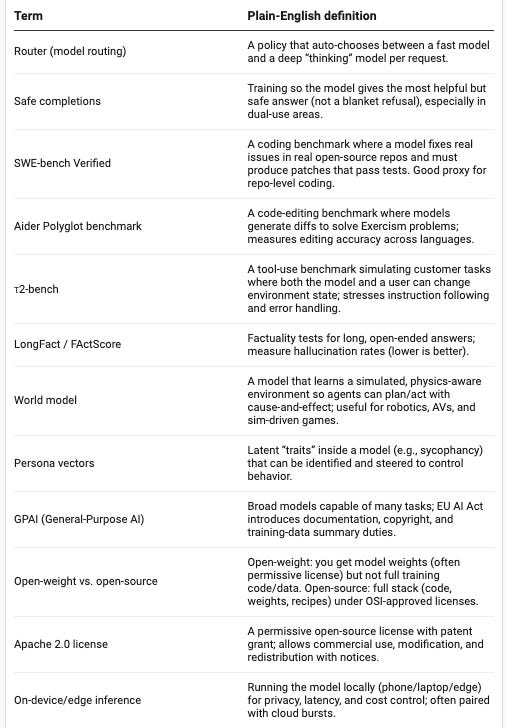
Discussion:
Why big tech companies are opening their ai models < Open AI, llama, and xAI>
Finances:
1. Cost Savings: According to a recent study< AI at Meta Study: Open Source AI as Economic Catalyst > , companies would spend 3.5x more on AI development without open-source software. Open models massively cut R&D costs by leveraging global developer contributions and shared innovation.
2. Productivity Boost: Nearly 9 in 10 organizations that adopt open-source AI report increased productivity and significant cost savings.<McKinsey & Company: Open Source Technology in the Age of AI>
3. Widespread Adoption: Open-source AI is now used by 42% of enterprises (outpacing proprietary solutions at 36%), becoming a new industry backbone. Positive ROI: IBM found 51% of companies using open-source AI see measurable, positive returns.
-- Strategic:
1. Ecosystem Domination: Open-sourcing accelerates adoption, making these models the industry standard and ensuring their tools become foundational for future innovation.
2. Accelerated Innovation: Crowdsourced improvements and community-driven development mean faster bug fixes, creative applications, and robust, auditable code. Companies like Meta report that open-source AI is a base for their model growth
3. Risk & Regulation: Open models are more transparent and auditable, making them easier to align with new AI safety and compliance standards—a growing concern worldwide.