
Essential guide of Prompt Engineering for Software Engineers
Prompt Engineering for Software Engineering: From Getting Started to AdvancedA hands-on guide to crafting AI prompts that actually deliver solid code, from basic queries to pro level skills.


TL;DR:
Prompt engineering is the “wiring” between human intent and model output — especially in code tasks
Start simple: Use zero-shot prompts for quick code snippets, then layer in examples for consistency.
Go advanced: Chain-of-thought prompting breaks down complex problems like algorithm design step-by-step.
Best for devs: Tailor prompts to models like ChatGPT or Claude for tasks from debugging to architecture.
Try it: Copy my example prompt for refactoring code and tweak it in your IDE.
Introduction:
Bonjourno, fellow coders. I’m Malik, the guy behind Code Meet AI, where we experiment with AI to stay ahead without getting replaced.
In this chapter, I will teach the most important skills in the new AI era: Prompt Engineering.
LLM problems
When working with LLM, we get into these problems:
Hallucinations — “it made up a function that doesn’t exist.”
Style drift — the model uses different conventions mid-chunk.
Unclear logic lineage — you can’t see why it made a choice.
Long tasks break — the model forgets earlier instructions in big prompts.
Model-specific quirks — what works on GPT may misfire on Claude, or Gemini.
Approach to guide LLM
To make the AI give you the desired output, we have four approaches:
1. Prompt Engineering
The Simple Idea: Asking the right question in the right way.
Think of this as learning how to talk to the chef to get the best answer. You don’t just say “Make food.” You give clear, specific instructions.
Analogy: You have a talented, general-purpose chef who has read millions of recipes (this is a base LLM like ChatGPT). You need a vegetarian lasagna recipe.
Bad Prompt: “Tell me about lasagna.” (You might get a history lesson on lasagna).
Good Prompt: “Provide a detailed recipe for a vegetarian lasagna that serves 4, uses spinach and zucchini, and takes less than 60 minutes to prepare. List the ingredients first, then the steps.”
In a Nutshell: You’re not changing the chef’s skills; you’re just getting better at giving them instructions. It’s the easiest and first thing you should try.
2. RAG (Retrieval-Augmented Generation)
The Simple Idea: Giving the AI a “cheat sheet” of specific information before it answers.
The chef is smart, but they don’t know your restaurant’s secret family recipes or the latest dietary guidelines. With RAG, you give them that specific information to use.
Analogy: You want the chef to answer questions based on your secret family cookbook, which they’ve never read.
Retrieval: You ask, “What’s the secret ingredient in Grandma’s pie?” The system quickly looks through your family cookbook (the database) and finds the relevant page.
Augmented Generation: It then hands that page to the chef and says, “Now, using your general cooking knowledge and this page, answer the question.”
The chef then answers: “Based on the provided recipe, the secret ingredient in Grandma’s apple pie is a touch of cardamom.”
In a Nutshell: RAG connects the AI to external, up-to-date, or private information sources to provide accurate, context-specific answers without retraining the model. It prevents “hallucinations” by grounding the answer in facts.
3. Fine-Tuning
The Simple Idea: Re-training the chef to specialize in a specific cuisine.
This is not about giving instructions or a cheat sheet; it’s about permanently changing the chef’s core knowledge and style through additional training.
Analogy: You have a great general chef, but you are opening a sushi restaurant. You send them to Japan for an intensive, months-long training course on sushi. After this, their fundamental understanding of fish, rice, and technique is permanently altered. They are now a sushi specialist.
Before fine-tuning: If you ask for a “California Roll,” they might describe it generally.
After fine-tuning, they will provide an exquisitely detailed, authentic recipe because they have internalized the principles of sushi.
In a Nutshell: Fine-tuning changes the model’s weights (its “brain”) to make it an expert in a specific domain, style, or task. It’s more expensive and time-consuming, but creates a deeply specialized model.
4. All Approach → A Combination of All Techniques
The Simple Idea: Creating the ultimate, world-class, specialized chef.
You don’t just use one method; you use all of them together for the best possible result.
Analogy: You run a high-end, farm-to-table restaurant.
Fine-Tuning: You first send your chef to a specialized course on “Modern Californian Cuisine” to change their core skills.
RAG: You give the chef access to a live database of what ingredients are fresh and available from the local farms today.
Prompt Engineering: You then ask the perfect question: “Using today’s fresh ingredients from our database, create a tasting menu for 6 that includes a pescatarian main course, and pair each course with a wine from our Napa Valley-focused list.”
The chef combines their specialized training (Fine-Tuning), the fresh data from the farm (RAG), and your clear instructions (Prompt Engineering) to create a masterpiece menu that would be impossible with any single technique alone.
In a Nutshell: This is the most powerful approach. You create a specialized model (Fine-Tuning), connect it to your private data (RAG), and interact with it using best practices (Prompt Engineering) to solve complex, real-world problems.
Why Prompt Engineering
Prompt engineering is the easier one. It is the ability to express exactly what you need to AI, The idea is to give as much Context, an example, and a proper way to explain what you need easily and pretty straightforwardly. It is not only in Software engineering, where the gap is bigger, but also in the type of LLM communication. The amount of data that the LLM has learned about, and compared to our small request, will always leave the LLM a space to be creative: Creative here is called “Hullicination”, which wis hat kills the trust now.
There are different courses and books about that: the best one is from google in this link: https://cloud.google.com/discover/what-is-prompt-engineering. It will help you understand them and structure them
Prompt Engineering Technics:
In this chapter, I will go into each type of Prompt engineering and provide examples for each one of them, so you will be able to understand and fully digest it
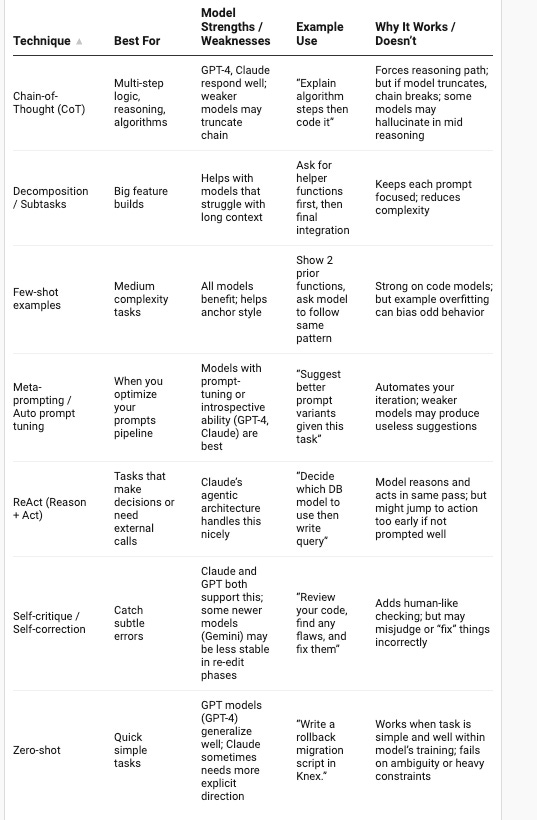
1. Zero-shot Instruction
Describe the task, constraints, and output format
Bad Example:
Make a login function”Too vague - no context, no framework, no constraints.
Good Example:
“Create a Node.js Express route for user login that:
- Accepts email and password in the request body
- Validates input fields aren’t empty
- Returns 400 for missing fields, 401 for invalid credentials
- Uses bcrypt to compare passwords
- Returns a JWT token on success
- Returns JSON response with appropriate status codes
Use async/await and proper error handling.”Clear task, specific framework, constraints, and output format.
2. Few-shot Examples
Provide 1–3 examples of input → output
Bad Example:
“Write functions in this style:
function add(a,b) { return a+b }
Now write a user validation function”Irrelevant example that doesn’t demonstrate the desired pattern.
Good Example:
“Create React component validation functions in this style:
Example 1: Email validation
const validateEmail = (email) => {
const regex = /^[^\s@]+@[^\s@]+\.[^\s@]+$/;
return regex.test(email)
}
Example 2: Password strength
const validatePassword = (password) => {
return password.length >= 8 &&
/[A-Z]/.test(password) &&
/[0-9]/.test(password);
}
Now create: Phone number validation for US format (xxx-xxx-xxxx)”Shows exact style, pattern, and complexity level expected.
3. Chain-of-Thought (CoT) Prompting:
Ask the model to reason in steps before final answer
Bad Example:
“Fix this React Native navigation error”No reasoning, just expects a direct answer.
Good Example:
“Analyze this React Native navigation error and reason step by step:
ERROR: ‘NavigationContainer is not configured’
Step 1: Check if NavigationContainer is properly imported
Step 2: Verify the navigation structure and nesting
Step 3: Look for missing dependencies or incorrect versions
Step 4: Check for proper initialization of navigation refs
After reasoning, provide the fix for this code:
[code snippet here]”Forces systematic reasoning before jumping to solutions.
4. Decomposition / Subtask Chaining
Break big tasks into smaller prompts (e.g. prompt for validation, then prompt for DB logic, then prompt to combine).
Bad Example:
Build a complete React authentication system with login, logout, and protected routes”Too complex for one prompt - will produce messy or incomplete code.
Good Example:
Prompt 1: “Create a React context for authentication state management”
Prompt 2: “Build a login form component with validation using the auth context”
Prompt 3: “Create a protected route wrapper that redirects unauthenticated users”
Prompt 4: “Combine all pieces into a working authentication system”
Breaks the complex task into manageable, testable components.5. ReAct (Reasoning + Action)
The model both reasons and acts (e.g., “Explain, then generate code”).
Bad Example:
“Query the database and return user data”No reasoning about the approach.
Good Example:
“Let’s solve this step by step:
REASONING: I need to fetch user data from a MongoDB database in Node.js. First, I should establish database connection, then create a query to find users, handle potential errors, and format the response.
ACTION: Write a Node.js function that:
1. Connects to MongoDB using mongoose
2. Queries the ‘users’ collection for active users
3. Handles connection errors and query errors
4. Returns only name and email fields
Code:
[generated code here]”Explicitly separates reasoning from the action/code generation.
6. Self-critique / Self-correction
At the end, ask the model to review its output, find mistakes, and fix them.
Bad Example:
“Write a React useEffect hook for data fetching”No review process for potential improvements.
Good Example:“Write a React useEffect hook for fetching user data from an API.After generating the code, review it for:
- Proper dependency array usage
- Cleanup of ongoing requests
- Error handling
- Loading state management
- Memory leak prevention
Then provide an improved version fixing any issues found.
Builds in quality assurance by having the model critique its own work.
7. Iterative Feedback & Prompt Auto-tuning
Bad Example:
“Make a responsive navbar” → “No, better” → “Still not right”Vague feedback that doesn’t help improve results.
Good Example:
Initial Prompt: “Create a responsive navbar for React with React Router”
Feedback: “The navbar works but has accessibility issues. Please add:
- Proper ARIA labels
- Keyboard navigation support
- Focus management
- Screen reader compatibility”Improved Prompt:“Create an accessible, responsive React navbar with React Router that includes ARIA labels, keyboard navigation, and screen reader support. Use semantic HTML and ensure WCAG 2.1 AA compliance.”Final Meta-prompt: “Based on my previous requests for navbar components, generate an optimized prompt template that consistently produces accessible, production-ready React navigation components.”Shows learning from iterations to create better future prompts.
Prompt engineering Resources to dive deeper
Anthropic’s prompt engineering guide (Claude) docs.anthropic.com
Google Cloud / Vertex AI prompt design docs Google Cloud+1
GitHub repo “system-prompts-and-models-of-ai-tools” (great real-world agents & system prompts) GitHub
PromptingGuide.ai overview promptingguide.ai
Personal Approach:
For me, when it comes to the usage of coding tools or LLM in general, I take into account different architectures and what the best practices are for each model.
Model-specific notes:
Claude / Claude Code: tends to prefer explicit instructions and structured reasoning (CoT) with clear steps. It’s more robust when you break tasks and provide manifest-style rules.
GPT (OpenAI models): tends to be more flexible with examples; can “fill in gaps” more courageously. But hallucinations are more common in longer prompts.
Gemini (Google): younger ecosystem; strong on multimodal tasks, but reasoning chains beyond a certain depth may degrade. Their architecture is tuned more for “sense-making” than deep algorithmic logic. Google AI for Developers
Smaller / Domain-specific models: often struggle with chain-of-thought, so simpler direct prompts or decomposition are safer.


Conclusion
The best way for me to learn about Prompt engineering is the following: Try, Test, Feedback, and Iterate. It is the best approach, this type of prompt engineering are mostly best practice, but you never get to the full approach if you don’t test and check why and how it is working.
I tend to be the type of person who loves chains of thought, as it is more about dumping my thoughts and checking with the LLM. Another approach is to use LLM to create a prompt to guide LLM. really helpfull
The breakdown of diferent prompt engineering techniques is really practical. The chain of thought approach makes sense for debugging complex issues. I apprecate how you compared each model's strengths, especialy noting Claude preferes structured reasoning while GPT fills in gaps more readily.
Brilliant. Your chef analogy perfectly illustrates prompt engineering, though I truely find it's also about understanding each LLM's peculiar limitations.